ADRENALIN 2023: Building Energy Load Disaggregation Challenge
Background
Buildings account for a significant portion of global energy consumption and reducing energy use in buildings is critical to meeting global emissions reduction targets.
Building energy load disaggregation involves identifying individual appliances or devices that consume energy within a building, which is essential for implementing targeted energy efficiency measures. The accurate disaggregation of individual appliance energy consumption from the total building energy consumption is a complex problem and has important implications for building owners and operators, energy providers, and consumers. Understanding how much energy individual appliances consume can enable building owners and operators to optimize energy consumption, reduce energy costs, and improve overall energy efficiency.
The energy load disaggregation problem has been the focus of research in the energy sector for many years, and it remains a challenging problem due to the complex and diverse nature of appliances and their energy usage patterns. Traditional methods for load disaggregation rely on installing sub-meters for each appliance, but this approach is costly and impractical for large-scale applications.
The Building Energy Load Disaggregation Challenge aims to develop accurate and scalable algorithms for disaggregating weather-dependent building energy use. The main goal of the competition is to drive innovation and progress in the field of building energy management, which can lead to significant energy savings and reductions in greenhouse gas emissions.
Problem statement
The accurate disaggregation of weather-dependent building energy use from the total building energy consumption is a complex problem that requires the development of accurate, efficient and scalable methods. This competition seeks to address this challenge by promoting the development of innovative solutions to the energy load disaggregation problem, enabling building owners and operators to optimize energy consumption, reduce energy costs, and improve overall energy efficiency.
The competition will challenge participants to develop efficient, effective, and scalable algorithms that can accurately identify energy use related to heating/cooling from the total building energy consumption, while taking the following key challenges into account:
- Accuracy: Load characteristics such as cooling or heating load, and their sub-loads are difficult to estimate because they cannot be divided into finite states. This makes it challenging to accurately disaggregate loads with complex characteristics. To address this issue, the competition will focus on developing methods that incorporate additional features to improve accuracy in load disaggregation.
- Complexity: Developing models for load disaggregation requires prior knowledge of specific device features in some methods. Deep learning methods can extract these features automatically. However, modern methods often tend towards deeper and deeper structures, which leads to slow training speed, high calculation cost, and reduced learning ability due to an excessive number of parameters. Therefore, the competition will prioritize developing models that can accurately disaggregate loads without requiring prior knowledge of specific device features while maintaining learning ability and avoiding the aforementioned drawbacks of deepening the model structure.
- Generalization: Buildings can be quite different from one another in terms of size, design, construction materials, appliances, and occupants’ behavior. Many of the disaggregation techniques used are trained and tested on the same buildings, or set of similar buildings, which leads to poor generalization between different buildings. The dataset for this competition includes multiple, various buildings, and promotes the creation of models with good inter-building generalization.
- Scalability: As the number of buildings increases, so too does the volume of data that needs to be processed. This includes not only the energy usage data but also the weather data and metadata associated with each building. Processing this much data can be computationally expensive and time-consuming, which poses a challenge for scalability. The competition will focus on developing scalable methods to handle large amounts of data, efficiently disaggregate weather-dependent load blocks, and accurately predict energy consumption patterns across diverse building types and climatic conditions.
Data Set
Access to the dataset will be shared here, once it is available.
The usage of external data is allowed in this competition, as long as it is free and publicly available. The competitors must ensure that all data they use is freely available to all participants, and post access to the dataset on the competition forum before the end of the competition.
Participation and Submission
Participation on the competition is done throug CodaLab, as follows.
-
To register a Codalab account go to https://codalab.lisn.upsaclay.fr/accounts/signup
- Go to the competition’s page: (link will be available at a later date)
- Navigate to the “Participate” tab to accept the terms and conditions and register for the competition.
The competition will use result submission. Participants are required to locally compute the predictions and format it as a CSV file. The file needs to be zipped for submission and uploaded through the competition’s Codalab page, under the participate tab.
Submissions during the final, evaluation round are also required to submit a detailed documentation of their solution.
An example submission file will be available along with the dataset. This will show the exact format necessary for the submission.
Evaluation Criteria
The competition will use Mean Absolute Error (MAE) as the main metric of the leaderboard, and to determine the winners. Additionally, the leaderboard will also show Relative Mean Absolute Error (RMAE), which is a normalized version of MAE, for easier interpretation, and Mean Absolute Percentage Error (MAPE), which expresses the average deviation relative to the truth. They are calculated as follows:
Where ´y´ is the ground truth, ´x´ is the predicted value, and ´n´ is the number of time instances.
The competition will have three phases:
- The first two phases will run a public leaderboard.
- In the last phase, the winner candidates will work together with the companies to ensure the developed model work as promised.
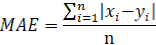
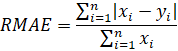
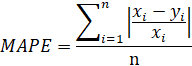
Timeline
The Dates will be announced in the third quarter of 2023!
- Phase I (Warm-Up Round, TBD)
In this phase, a and participants will be given a chance to familiarize themselves with the competition environment, training data, and documentation, and also allow the raising of issues. There will be a public leaderboard, where the scoring will be done against the training data. We will also create a solution example, and provide baseline models.
- Phase II (Validation Round, TBD)
This phase marks the beginning of the entry evaluation and ranking of submitted entries against a hidden dataset. A public leaderboard will be available where participants will see how their submissions rank against each other and how their latest submission ranks against other participants' submissions. At the beginning of this phase, the complete training dataset will be released.
- Phase III (Evaluation and Winner Round, TBD)
New submissions will be halted at the beginning of this phase. The submitted entries will be evaluated against a separate hidden dataset, on a private leaderboard. The final leaderboard and selected winners will be published.
Prizes
Coming Soon!
Rules
To ensure that the competition is conducted in a fair and ethical manner, and that all participants should hold to a high standard of conduct:
- Respect: Participants are expected to treat others with respect, regardless of their background, identity, or affiliation.
- Honesty: Participants are expected to be honest and truthful in their submissions, and not to plagiarize or copy the work of others.
- Integrity: Participants are expected to maintain the integrity of the competition and not engage in any activity that could compromise the fairness or accuracy of the results.
- Confidentiality: Participants are expected to keep the data provided for the competition confidential and not to share it with others.
- Legal Compliance: Participants are expected to comply with all applicable laws, regulations, and ethical standards.
- Consequences: Violations of the Code of Conduct may result in disqualification or other sanctions, as determined by the competition organizers.
Contact
Discussion forum
Participants can get in touch wit the organizers, and each other using the discussion forum on the competition’s Codalab page. The forum can be found at the following location: https://codalab.lisn.upsaclay.fr/forums/13292/
Pleas do not hesitate to contact us.
Sponsors
The prizes of this competition are sponsored by the Danish Energy Technology Development and Demonstration Programme (EUDP) fund

Coordinator
SDU Center for Energy Informatics, Denmark